This looks pretty cool, are there any comparisons to NLTK et al? The examples seem pretty straight forward and well commented, but overall Documentation is a bit lacking.
Now the really important question: Is it pronounced the same as a "mai tai" or more like "mitty" ?
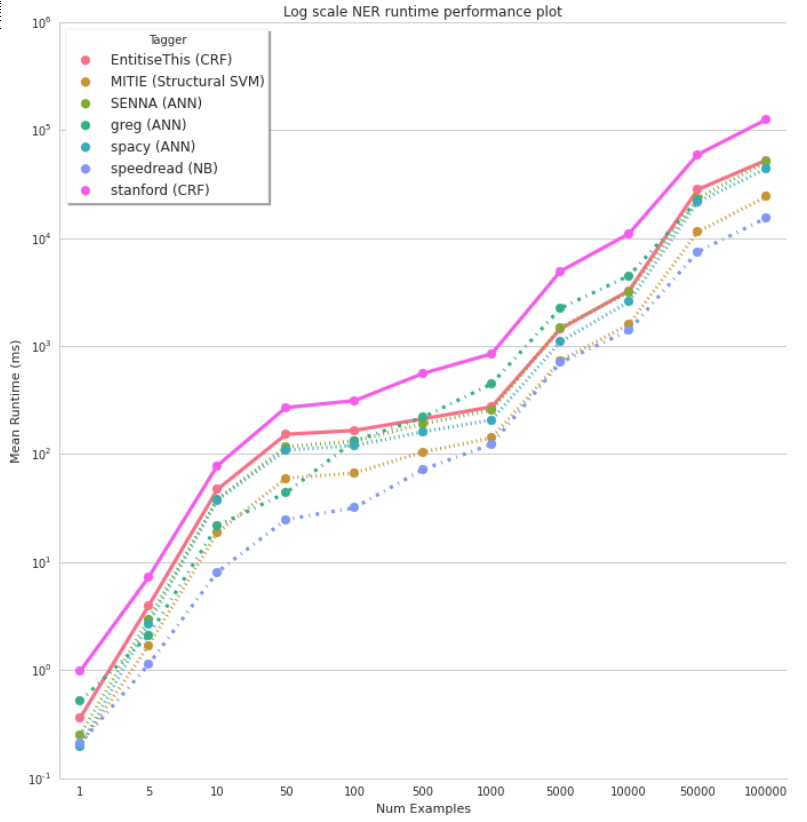
It's very fast after the model(s) have been trained. The training can take a long time, it might be something like N^4 where N is the number of distinct types of features. Something about intersecting planes for each dimension.
It is used in several DARPA programs including XDATA and MEMEX to name a couple. One of the committers is actually now a DARPA PM (Wade Shen) who has taken over some programs from a previous PM you may remember from MEMEX on 60 minutes.
As far as speed, once trained we used it as part of a batch job to enhance various types of freetext and semi structured text, and the performance was very good (I don't have numbers in front of me, but some groups should)
We also would wrap MITIE with a Tangelo wrapper so we could use it as a REST client (for other webapps to hit at runtime), posting freetext to it and getting back a list of entities and annotated freetext.
It can also work well on semi-structured text, for instance a table of semi-regular data that was pasted into a string, losing it's pagination/formatting. This requires a tailored model but works well.
The training of MITIE can be a bit challenging if you have too many types that might appear in similar locations in text. One of the DARPA teams built a MITIE trainer which allowed a SME to annotate text in a web ui to help build the model, which is then run against the corpus of data in batch.
The stock model is built on newspaper data, IIRC, so it may not be suited to something like, say, tweets or books.
I hope this helps. I highly recommend checking it out if your project needs something like this. A lot of man hours went into developing it, and the developers would love for it to gain traction and have the technology transfer outside academia/defense. Drop them a line or a pull request!
Note: there have been suggestions for including some rudimentary low-hanging-fruit post process techniques, like applying supplied regexes, whitelists, blacklists, pronoun dictionaries, etc. One variant was also looking to pull out relationships as well as entities as tagged fields.
Thanks for that explanation. I bookmarked the site but was going to pass on playing with it before reading your post. I am most interested in generating relationships between named entities. I can find NEs in my NLP code but I can't generate links like "owns", "located at", etc.
The "binary relation detection" looks interesting, and I'd like to know more about it. Are there any other NLP libraries that can perform similar functions?
{kind=link}
Now the really important question: Is it pronounced the same as a "mai tai" or more like "mitty" ?